
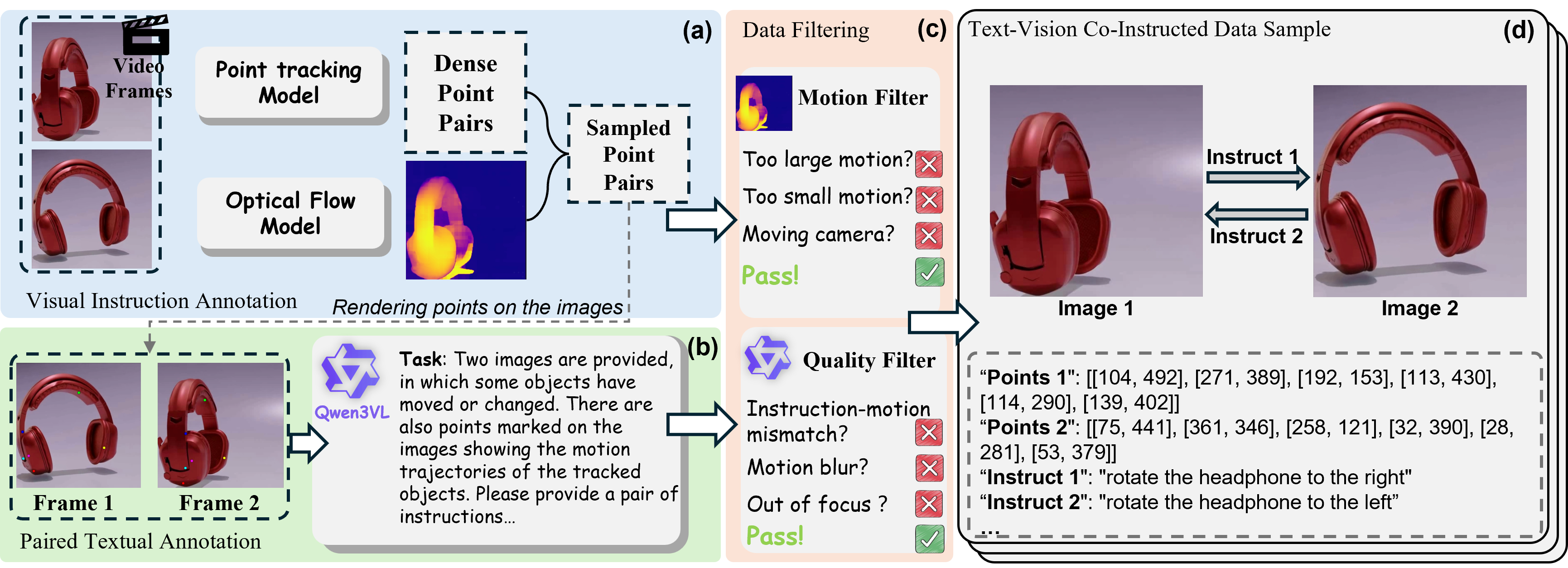
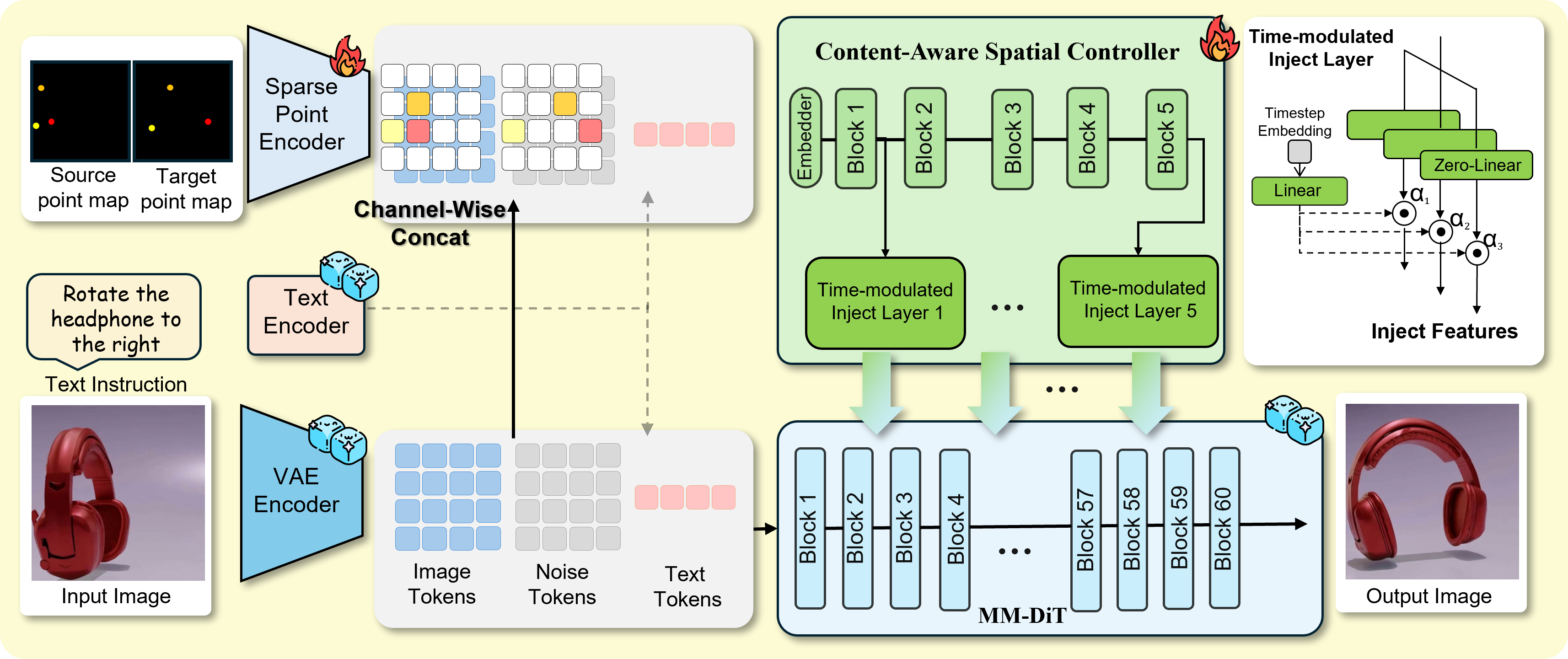
Existing image editing methods can be generally categorized into textual instruction-based and visual prompt-based ones. Textual instructions are semantically expressive, but are limited by the coarse granularity of spatial control of the editing results. In contrast, visual prompts such as drag and point can provide precise spatial guidance, but are limited by the inherent ambiguity in semantic intent. To unify the strength of textual and visual prompts, we present Text-Vision Co-Instructed Image Editing, which jointly models textual instructions as semantic intent and sparse visual instructions as spatial guidance, aiming to achieve precise and intent-faithful image manipulation. To this end, we first construct a textual-visual instruction paired dataset with more than 23K samples derived from dynamic videos, enabling aligned supervision for cross-modal instruction. We then propose TV-Edit, a Textual-Visual instruction unified Editing framework to contextualize drag or point-based visual instructions with image-text semantics and lift them into semantic-aware control representations for pretrained editing backbones. By integrating semantic intent and spatial constraints, TV-Edit leads to more precise spatial control, less instruction ambiguity, and stronger structural consistency than text-only or drag-based alternatives. Finally, we establish TV-Edit-Bench, a deliberately designed benchmark to evaluate semantic faithfulness, spatial alignment, and visual consistency with ground-truth references and controlled textual-visual variations for reliable assessment. Our experiments across multiple editing backbones demonstrate that TV-Edit consistently yields more precise and intent-faithful edits, significantly outperforming state-of-the-art instruction-based and drag-based baselines. Data, model, and codes will be released.
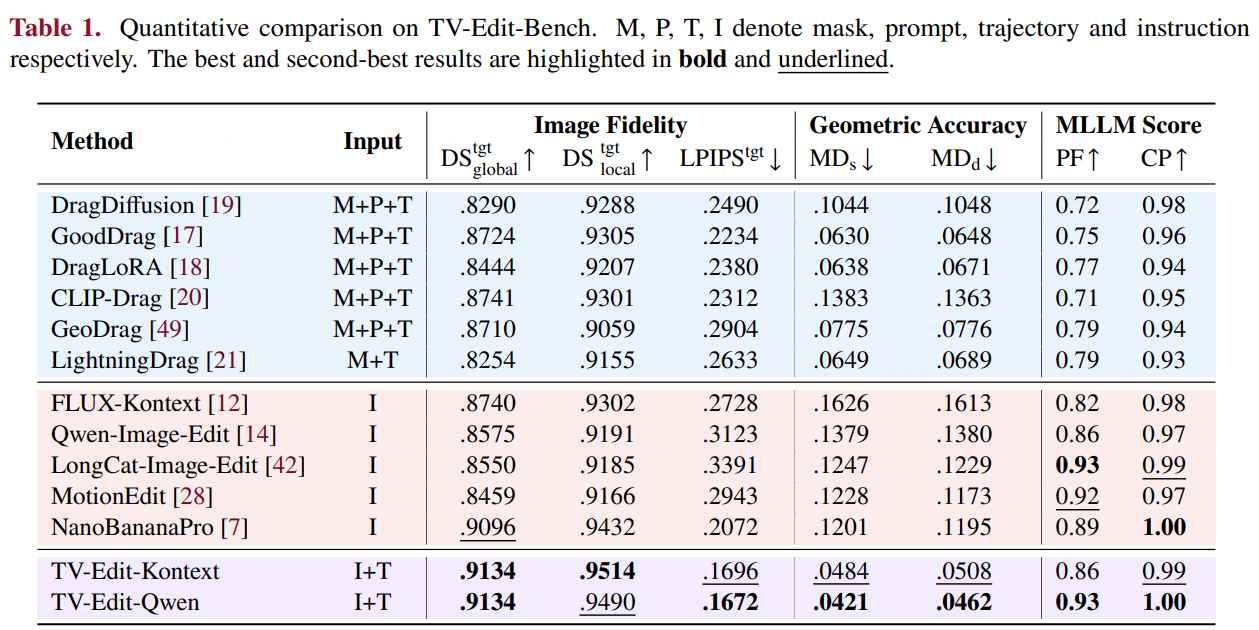
We construct TV-Edit Bench with 120 paired editing samples collected from real videos, I2V models, and image editing models. We design two sub-tasks with controlled variables to evaluate the semantic and geometric following abilities of different methods.



@article{xie2026text-vision,
title={Text-Vision Co-Instructed Image Editing},
author={Xie, Chenxi and Wu, Yuhui and Yi, Qiaosi and Zhang, Lei},
year={2026},
journal={arXiv preprint arXiv:2606.16767},
}